
Recent 3D face reconstruction methods have made significant advances in geometry prediction, yet further cosmetic improvements are limited by lagged albedo because inferring albedo from appearance is an ill-posed problem.Although some existing methods consider prior knowledge from illumination to improve albedo estimation, they still produce a light-skin bias due to racially biased albedo models and limited light constraints.
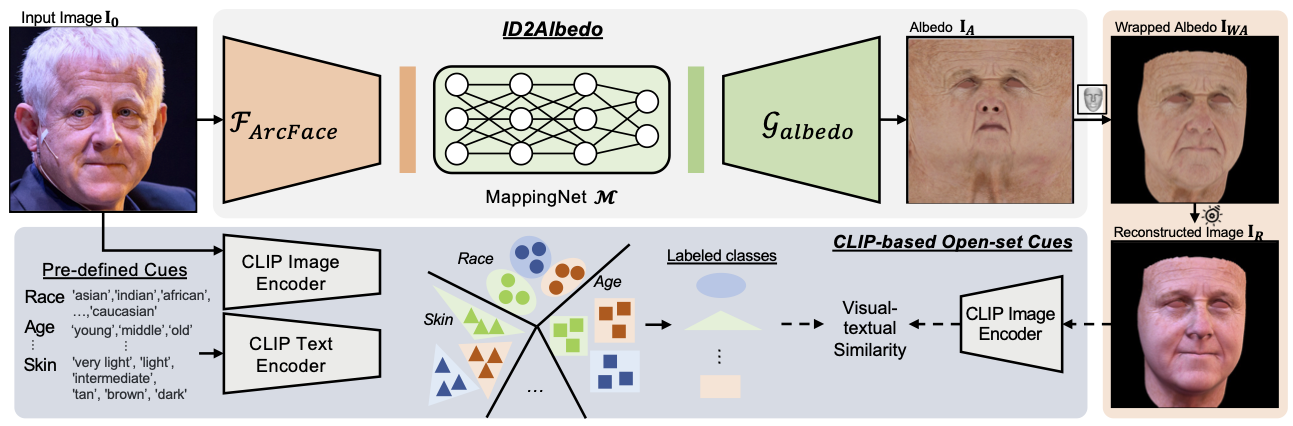
In this paper, we reconsider the relationship between albedo and face attributes and propose an ID2Albedo to directly estimate albedo without constraining illumination. Our key insight is that intrinsic semantic attributes such as race, skin color, and age can be used to constrain the albedo map. We first introduce visual-textual cues and design a semantic loss to supervise facial albedo estimation. Specifically, we pre-define text labels such as race, skin color, age, and wrinkles. Then, we employ the text-image model (CLIP) to compute the similarity between the text and the input image, and assign a pseudo-label to each facial image. We constrain generated albedos in the training phase to have the same attributes as the inputs. In addition, we train a high-quality, unbiased facial albedo generator and utilize the semantic loss to learn the mapping from illumination-robust identity features to the albedo latent codes. Finally, our ID2Albedo is trained in a self-supervised way and outperforms state-of-the-art albedo estimation methods in terms of accuracy and fidelity. It is worth mentioning that our approach has excellent generalizability and fairness, especially on in-the-wild data.
Please note that due to the timing of the publication, we clarified the paper used the BFM version of the TRUST model for visual comparison.
@InProceedings{Ren_2023_CVPR,
author = {Ren, Xingyu and Deng, Jiankang and Ma, Chao and Yan, Yichao and Yang, Xiaokang},
title = {Improving Fairness in Facial Albedo Estimation via Visual-Textual Cues},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2023},
pages = {4511-4520}
}